



.png)

Build intelligent, secure and accurate GenAI assistants for your customers, support and sales teams



© 2025 Alltius Inc
It has been over 100 days since the LLM blitzkrieg hit people and businesses alike. While many people have been at LLM centric solutions for months before that event, the virality was unprecedented. Some entities have been early adopters (e.g. Expedia), even when their public image is one of inertia (e.g. AirIndia), while others are adopting a measured approach. The caution is primarily on account of privacy and security concerns.
This wave is not so much about creative copywriting as much it is about using AI to truthfully answer questions from existing information. But can LLMs do that? Or at least help you do that? On their own, they are brilliant language completion tools and not fact dispensing oracles. Chat layers of LLMs seem to fictionalise a lot of stuff when one uses them for both.
As part of our user research exercises and various customer pilots, we spoke with several professionals who have been championing the cause of using coachable assistants for getting quick answers (check out KNO Plus). Here are some of them.
Here are some synthesised findings from our conversations.
Most believe that the text generative AI applications for businesses will need to evolve across two generations.
Plugins and applications that can answer questions. The consumer could be an employee of the business or their end user.
Applications that can consume simple instructions in natural language and guide users to complete a task. e.g. creating an ‘opportunity’ Salesforce CRM (without opening the application itself)
Most applications are in the Level 1 phase - they are trying to answer questions. At Alltius, we are not only answering questions but also finding them from sources of choice in communicated in a medium of convenience (e.g. widgets, web apps, APIs, plugins and more).
Most Level 1 use cases are analogous to a human completing the task, but it could be for oneself or for someone else. For example,
In all the use cases, the expectation is that a ‘Level 1 Assistant’ will meet the same bars of trust as one would place on humans in order to get a well-synthesised accurate answer. So what would it take to earn this trust?
This trust, they say, manifests along two axes.
Remember that the user is okay not reading through information and vetting for hours. Instead, he or she is willing to place trust in a generative AI powered assistant. It is natural that users are expecting the answers to have :
This is precisely why businesses will easily trust applications that pull SQL queries and manipulate graphs using natural language instructions rather than an AI co-pilot that constructs answers for questions.
At Alltius, our AI assistants get coached in seconds and answer even more quickly. For our large Enterprise customers, we spend disproportionately larger time on fine tuning models to meet stringent precision and recall metrics even before going live. The reference sources are clearly laid out and customers can pressure test in a convenient playground.
This brings us to the second axis.
Can you not send the information to the LLM please? Can we set your engine up in our cloud?
It is natural that businesses worry so much about their data. However, the hyperventilation is spread across a spectrum of data types, primarily driven by how many people should have access to it. If we were to grade it, they would sit in five buckets.
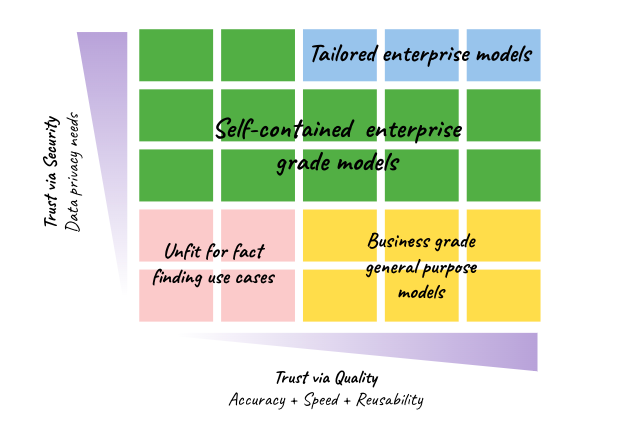
Three very distinct solution spaces emerge as a result.
At Alltius, we are engaging with customers in buckets 1 and 2. While we are offering out of the box AI assistants to train on publicly available information, we are also creating closed environments and insourced language models for large enterprises with bank grade privacy and security protocols.
Please tell us how you feel about this topic. If you have a use case to share or discuss you can contact us here.
